Skip to content
Skip to content What belongs in your robots.txt, what must never be blocked, and the audit process that catches the errors already costing you visibility.
In 2024, a well-established e-commerce brand experienced a routine site update that inadvertently altered their robots.txt file. Within 48 hours, organic traffic had dropped 58%.
Revenue losses mounted while their development team scrambled to diagnose the problem. By the time the error was found and corrected, the recovery process took weeks.
This is not a cautionary edge case. 25% of websites suffer from crawlability problems directly attributable to robots.txt errors. 73% of websites have critical technical SEO issues actively undermining their search visibility.
And only 31% of businesses conduct technical SEO audits more than once per year — meaning the majority are operating with configurations set during the initial site build and never reviewed again.
For businesses across the GTA, this invisible configuration file can be the difference between steady lead generation and a traffic collapse that no content investment or link building campaign can overcome.
Why This File Is Deceptively Dangerous
Robots.txt is a plain-text document in the root directory of your website — accessible atyourdomain.ca/robots.txt — that tells search engine crawlers which parts of your site they’re permitted to access.
When Googlebot visits your site, it checks this file first. Done correctly, it guides crawler resources toward your most valuable content.
Done incorrectly, it locks search engines out of your most important pages without any visible error or warning.
What makes it particularly hazardous for non-technical business owners is the gap between apparent simplicity and actual consequence.
The syntax is straightforward. But a single missing slash, an incorrectly placed wildcard, or a directive applied to the wrong user agent can cascade into significant indexation problems within days. The file that was configured once at site launch and never opened since is a live liability.
The Mistakes We Find Most Consistently
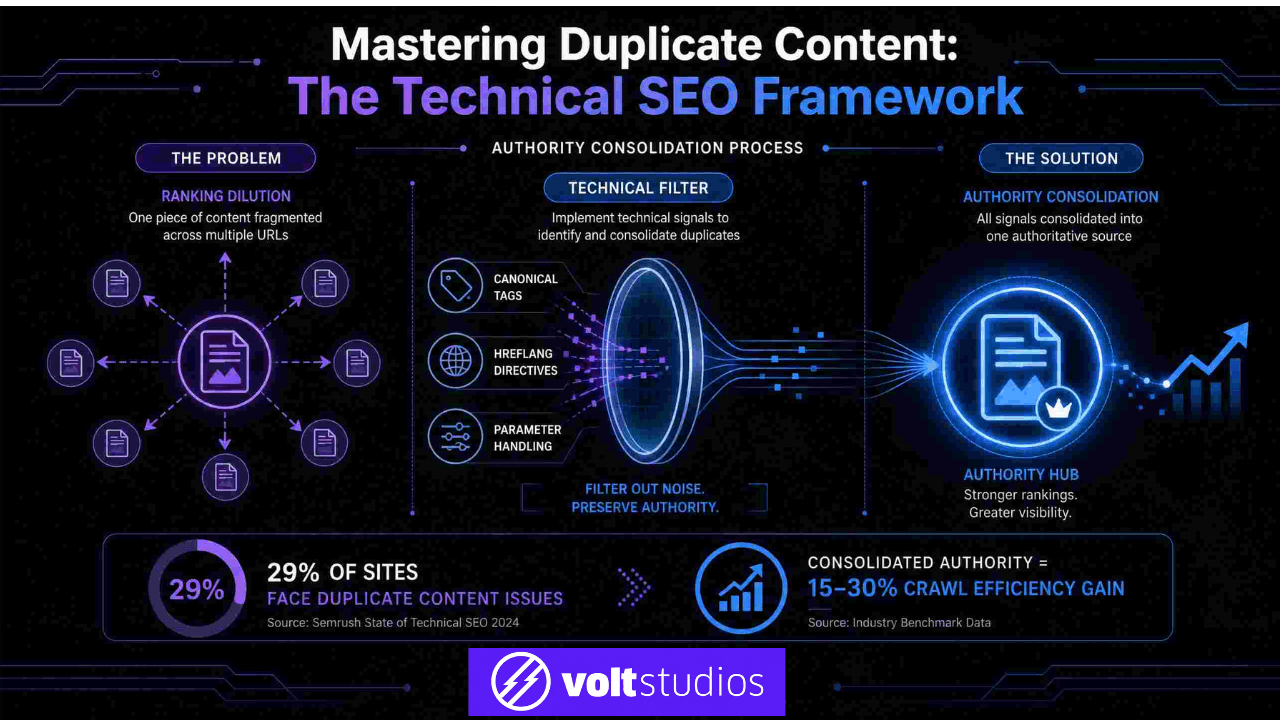
Accidentally blocking important content pages is the most catastrophic error category. A wildcard directive intended to block a specific subfolder extends to cover product pages, service pages, or blog posts.
We’ve audited GTA-based retail and professional services sites where entire category hierarchies were blocked from indexing — thousands of pages invisible to Google while the business continued investing in content creation without understanding why rankings were stagnant.
Blocking CSS and JavaScript is a legacy mistake that persists on sites built years ago when this was actually recommended.
Today, when Googlebot cannot access stylesheets and scripts, it cannot render pages properly. It can’t evaluate content quality, identify structured data, or assess page experience signals — all of which influence rankings. If it renders on the page, it must be accessible to Googlebot.
Incorrect syntax creates unintended sweeping consequences. Robots.txt is unforgiving. A misplaced asterisk, an incorrect directory path, a directive applied to User-agent: * when it was intended for a specific bot — any of these can block an entire website from being crawled.
Because most business owners never check robots.txt after site launch, these errors persist for months or years.
Failing to block what should be private is the opposite failure. Admin panels, staging environments, and development builds left accessible to crawlers allow Google to index duplicate or incomplete content, triggering duplicate content issues and diluting domain authority signals.
Staging sites carried into production after a redesign — where broad blocking was deliberately applied — immediately suppress all organic visibility.
This scenario causes a significant proportion of the dramatic traffic-drop cases we investigate for clients following a site rebuild.
Not updating after migrations is where the accumulation happens. Robots.txt is frequently overlooked during the highest-risk events in a site’s technical history.
What Should and Shouldn’t Be Blocked
Block admin panels and backend directories without exception — /wp-admin/, /wp-login.php/, and similar backend access points.
No scenario exists where having these pages indexed benefits the business, and leaving them accessible creates unnecessary security exposure.
Block internal search result pages. When users search within a site, the resulting URLs generate near-infinite combinations of low-value, near-duplicate pages.
Allowing these to be crawled is one of the most consistent crawl budget drains we identify on e-commerce and content-heavy sites.
Block filtered and sorted product pages unless the filtered views offer unique, rankable value — which in most cases they don’t.
For GTA-based e-commerce businesses managing large product catalogues, unmanaged filter URL generation is a significant crawl waste problem.
Block user account pages, checkout flows, cart pages, and order confirmation pages. These are session-specific, provide no informational value to searchers, and should never appear in search results.
Never block CSS, JavaScript, or image files. Google renders pages like a browser. When rendering resources are blocked, Googlebot sees an unrendered shell. Rankings reflect that.
Modern sites rely on JavaScript for dynamic content loading, lazy-loading images, and schema markup injection — blocking JS means Googlebot may miss entire sections of content including product descriptions and pricing data.
Always declare your XML sitemap within the robots.txt file. This single line dramatically improves crawl discovery and takes seconds to add.
The Syntax That Determines Whether Rules Work
Every robots.txt instruction begins with a User-agent declaration identifying which crawler the following rules apply to. User-agent: * targets all bots.
User-agent: Googlebot applies rules exclusively to Google’s crawler. Disallow instructs crawlers to skip specific URLs or directories.
Allow overrides a broader Disallow rule for a more specific path — and more specific rules take precedence. Wildcards require precision.
The asterisk matches any sequence of characters and is useful for blocking URL patterns rather than fixed paths — but poorly constructed wildcard patterns are one of the most common sources of accidental over-blocking.
The dollar sign anchors a rule to the exact end of a URL, useful for targeting specific file types. Use both cautiously and test every implementation before assuming it works as intended.
How to Validate That It’s Actually Working
Writing the file is half the job. Validating it is where most businesses fall short. Google Search Console’s URL Inspection tool tests any specific URL to confirm whether Google can access and index it — if a page is being blocked by robots.txt, GSC flags it explicitly.
The Robots.txt Tester in GSC (under Legacy Tools for verified properties) simulates how the file behaves for specific user agents against specific URLs, letting you test before a live mistake costs rankings.
Server logs reveal exactly which URLs Googlebot is requesting, at what frequency, and what responses it’s receiving.
For large sites with complex directory structures, this is the most granular validation available. GSC’s Crawl Stats report shows how Googlebot is spending its crawl budget — sudden drops in crawl activity are often the first symptom of a robots.txt misconfiguration.
What Fixing This Delivered for GTA Businesses
A Mississauga e-commerce retailer had a wildcard rule — copied from a template without understanding — blocking their entire /collections/ directory, their primary product category structure.
Within six weeks of correcting the configuration and submitting an updated sitemap, crawled pages increased 340% and organic sessions from product pages rose 28%.
A Vaughan professional services firm had virtually no restrictions, meaning Googlebot was spending crawl budget on hundreds of low-value admin, calendar, and tag archive pages.
Implementing targeted Disallow rules and concentrating budget toward service and location pages improved average rankings for core service terms by 4.2 positions within three months.
A Scarborough restaurant group had accidentally blocked their /menu/ directory — their highest-converting page cluster — following a theme migration.
Organic traffic to menu pages had dropped 61% in 30 days. After correcting the rule, traffic recovered to pre-migration levels within 45 days.
These are not exceptional outcomes. They’re the predictable result of finding and fixing errors that were already there, silently working against every other SEO investment the business had made.
The Robots.txt File That Hasn’t Been Reviewed in 12 Months Is a Liability
A robots.txt file that hasn’t been audited since launch, since the last migration, or since the last theme update is an unquantified risk.
The businesses that maintain clean configurations — reviewed after every significant site change, validated regularly in Search Console, and aligned with actual crawl strategy — are the ones whose SEO investments compound as intended rather than leak through a misconfigured text file nobody has opened in two years.
If you want to know what your current robots.txt configuration is actually doing — which pages are being blocked that shouldn’t be, which directories are wasting crawl budget, and whether your rendering resources are accessible to Googlebot — we offer a free technical SEO audit for Canadian businesses that includes a full robots.txt review.
Book your free technical SEO audit →