Skip to content
Skip to content Why 29% of websites are undermining their own organic performance without knowing it — and the systematic approach to fixing it. Here’s an analogy that makes this concrete.
You build a house, then accidentally construct an identical one next door. Potential buyers split their attention between both properties, unsure which one to choose.
Search engines face the same dilemma with duplicate content — and the consequences for organic rankings are equally tangible. 29% of websites currently face duplicate content issues. The vast majority of business owners have no idea the problem exists.
After a decade of auditing and rebuilding SEO foundations for GTA businesses, duplicate content remains one of the most consistently overlooked technical issues we encounter — regardless of industry, website size, or marketing budget.
50% of websites use duplicate meta descriptions and 54% rely on duplicate title tags, compounding the problem at the most fundamental level of on-page optimization.
What Duplicate Content Actually Does to Your Rankings
Google doesn’t impose a traditional penalty for duplicate content — your site won’t be manually actioned simply for having similar pages. The practical consequences are just as damaging.
When multiple URLs contain substantially similar content, any backlinks, social shares, or engagement signals those pages earn get fragmented across all those URLs instead of consolidating on a single authoritative page.
Link equity dilutes. No single version accumulates enough authority to rank competitively. We’ve seen Toronto e-commerce businesses with product pages that should rank on page one sitting on page three because their link authority was split across six near-identical parameterized URLs.
Crawl budget compounds the problem. Every time Googlebot revisits a duplicate URL, that’s a crawl request not being spent on new, unique, or updated content that could actually drive traffic.
For large GTA websites in competitive categories — real estate, legal services, home improvement — wasted crawl budget translates directly into slower indexing and delayed visibility for the pages that matter most.
The third consequence is unpredictability. When search engines can’t determine the canonical version of content, they make the decision without you — and they frequently choose wrong.
We routinely audit sites where Google has selected a filtered, parameterized, or outdated version of a page as the primary result, while the optimized version the business actually wants to rank remains invisible.
Where Duplicate Content Comes From
Most of it is unintentional, and most of it is structural. URL parameters are the single largest source for e-commerce and database-driven websites.
A single product page accessible through sorting options, colour filters, size selectors, price ranges, session identifiers, and tracking codes generates dozens of URL variations pointing to identical or near-identical content. Without management, Googlebot crawls them all.
HTTP versus HTTPS, www versus non-www, trailing slash versus no trailing slash — each variation creates a separate URL that search engines may treat as distinct content.
All of these should redirect cleanly to a single canonical version, but they often don’t after platform migrations and site redesigns. Staging and development environments accidentally left accessible to crawlers create entire duplicate copies of live sites.
Printer-friendly pages and mobile-specific versions without proper canonicalization each add more copies. Paginated pages with identical title tags and meta descriptions compete internally for the same keywords. Near-duplicate content is the subtler problem.
A Mississauga HVAC contractor with 127 service area pages, each targeting a different GTA neighbourhood with templated content varying only by location name, has a near-duplicate problem that won’t resolve through canonical tags alone.
Those pages can’t rank because they’re all competing against each other and none of them is genuinely different enough to merit its own position.
The Technical Fixes That Actually Work
Canonical tags are the first line of defence. The rel=”canonical” element tells search engines which version of a page you consider the authoritative source.
Self-referencing canonicals — pointing a page back to itself — prevent search engines from assigning canonical status arbitrarily when a URL is accessible through multiple paths. Every page needs one, particularly product pages, paginated series, and any URL that could be reached through parameter variations.
Implementation rules that cannot be ignored: canonical tags must point to the final indexable URL, not a redirect chain. Canonicals and noindex directives must never conflict on the same page. Always use absolute URLs rather than relative paths.
URL parameter management requires a two-pronged approach: configuring parameter handling in Google Search Console to guide how Google interprets each parameter, combined with self-referencing canonical tags on every parameterized page pointing back to the clean URL. For large e-commerce sites, parameter consolidation typically delivers 15–30% improvements in crawl efficiency within the first quarter.
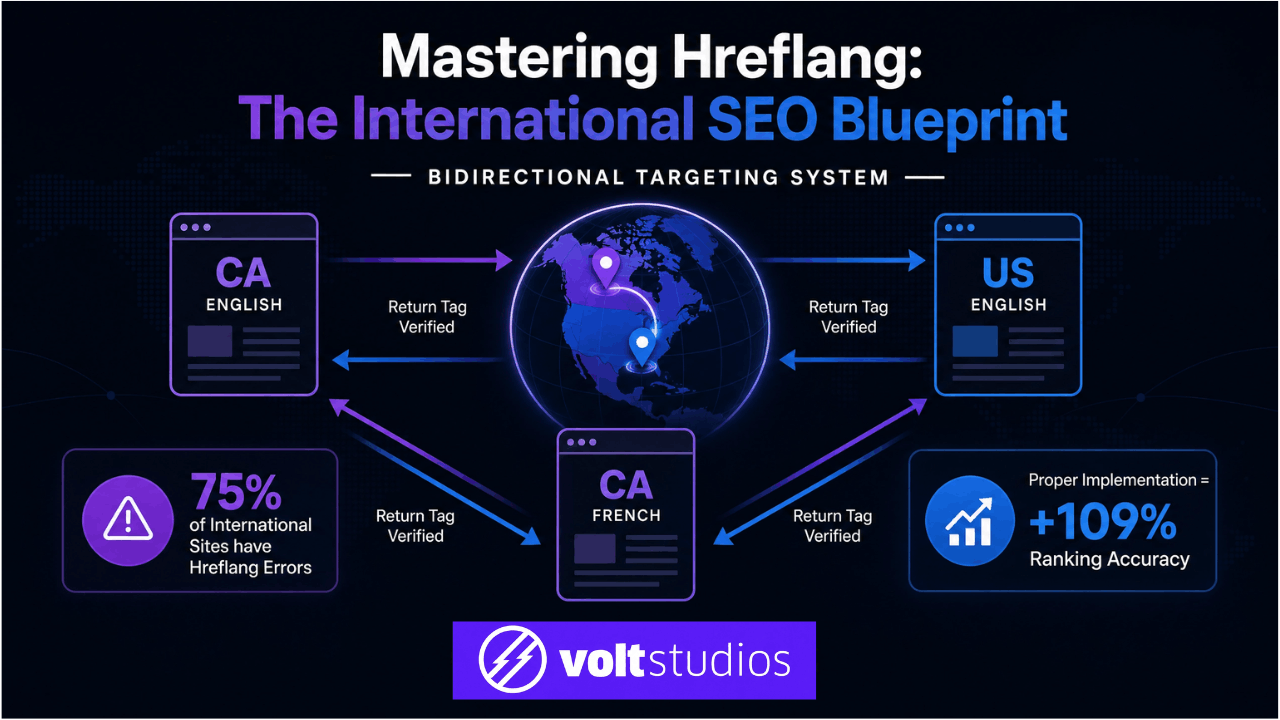
Hreflang implementation is critical for businesses serving multiple regional markets — and it’s among the most frequently misimplemented technical elements we encounter.
Over 67% of websites implementing hreflang encounter issues that create duplicate content problems and incorrect regional targeting.
The most common failure is missing return links: if page A references page B with an hreflang tag, page B must reference page A in return. When this reciprocity breaks, Google ignores both annotations entirely.
Pagination handling requires self-referencing canonical tags on each page in the series pointing to itself — not to the first page. Never noindex paginated URLs or block them via robots.txt; this cuts off PageRank flow to linked content and hides deep content from search visibility.
Each paginated page needs a unique URL, and secondary pages should be de-optimized with simple title tags to prevent them competing with the primary page.
Near-duplicate content requires differentiation, not just technical signals. Each service area page, location page, or product variant page must offer genuinely unique value to justify its existence in search results.
Neighbourhood-specific information, local landmarks, customer testimonials from that area, use cases specific to each product variant — content that could not logically appear on any other page.
When differentiation isn’t practical, consolidating thin pages into fewer, richer geographic or category pages produces better results than maintaining dozens of near-identical pages that dilute each other.
What This Delivers When Done Properly
A Mississauga HVAC contractor with 127 near-identical service area pages consolidated into twelve genuinely unique geographic service pages with proper canonical structure. Organic traffic increased 43% within four months — not because they had more pages, but because the remaining pages could actually rank.
A Toronto e-commerce retailer discovered that 60% of their crawl budget was being spent on parameterized filter URLs generating no revenue. After parameter consolidation and canonical fixes, crawl efficiency improved substantially and new product indexing accelerated from weeks to days.
The pattern is consistent: technical duplicate content fixes deliver measurable improvements in crawl efficiency, indexation rates, and organic visibility — often without new content creation or link building campaigns. The content investment and link equity were already there. The technical foundation was preventing them from working.
Why This Doesn’t Resolve Itself
Every day duplicate content goes unaddressed, search engines continue splitting ranking signals, wasting crawl budget, and potentially selecting the wrong version of content to display.
The businesses dominating organic search in competitive GTA markets aren’t necessarily the ones with the biggest content budgets. They’re the ones with the cleanest technical foundations.
A comprehensive technical audit identifies every instance of duplicate content across the site, prioritizes fixes by impact, and provides a clear implementation roadmap.
This requires deep technical analysis with professional-grade crawling tools — not surface-level scans that catch obvious issues while missing the structural ones doing the most damage.
If you want to know exactly where duplicate content is undermining your site’s organic performance — which pages are splitting your ranking signals, which parameter patterns are wasting your crawl budget, and what the priority order for fixing it is — we offer a free technical SEO audit for Canadian businesses.